Amazon Textract with expense analyzing

A Developer Advocate experiencing DevRel ecospace at Freshworks. Previous being part of the start-up Mobil80 Solutions based in Bengaluru, India enjoyed and learnt a lot with the multiple caps that I got to wear transitioning from a full-stack developer to Cloud Architect for Serverless!
An AWS Serverless Hero who loves to interact with community which has helped me learn and share my knowledge. I write about AWS Serverless and also talk about new features and announcements from AWS.
Speaker at various conferences globally, AWS Community, AWS Summit, AWS DevDay sharing about Cloud, AWS, Serverless and Freshworks Developer Platform
Amazon Textract now supports receipts and invoices processing which makes expense management systems analyze better with only receipt's or invoice's image or document. Read more about the announcement.
Key takeaways from the blog
- What is Textract?
- How Textract processes receipts and invoices
- Implementing Textract with NodeJS SDK
What is Textract?
Amazon Textract is a fully-managed Machine Learning service which extract textual information from documents and images. The Textract DetectDocumentText API is capable of detecting and extracting textual data which are handwritten or typed present either as texts, forms or tables in the document or image.
Common use-cases of Textract are -
- Data capture from forms.
- Automating certain processes similar to KYC process. {% twitter 1328351004903948288 %} {% twitter 1408507048111845386 %} And more use-cases available on Amazon Textract documentation.
Textract exposes the following SDK APIs for developers to integrate -
AnalyzeDocument(documentation)AnalyzeExpense(documentation)DetectDocumentText(documentation)GetDocumentAnalysis(documentation)GetDocumentTextDetection(documentation)StartDocumentAnalysis(documentation)StartDocumentTextDetection(documentation)
With Textract, the processing of images or documents can be handled synchronously or asynchronous.
StartDocumentAnalysis / GetDocumentAnalysis and StartDocumentTextDetection / GetDocumentTextDetection are the asynchronous implementation of Amazon Textract and whenever the action start (StartDocumentAnalysis and StartDocumentTextDetection) is executed, it returns a JobID which is referred to when getting the data.
Textract APIs are flexible to take either document/image buffer data or the object stored on S3 to process and extract textual information.
Python samples are available in - GitHub/awsdocs {% github aws-samples/amazon-textract-code-samples %} NodeJS samples are in an open pull request - {% github https://github.com/aws-samples/amazon-textract-code-samples/pull/18 %}
How Textract processes receipts and invoices
Textract AnalyzeExpense API processes the data and extracts the key information from the document such as Vendor names, Receipt number or Invoice number. AnalyzeExpense API is available only in the latest version of SDK, as this is one of the new functions available now. So ensure, you have updated your SDK.
Starting today, Amazon Textract adds the following capabilities for receipts and invoices: 1) Identifies Vendor Name - Amazon Textract can find the vendor name on a receipt even if it's only indicated within a logo on the page without an explicit label called “vendor”. It can also find and extract item, quantity, and prices that are not labeled with column headers for line items, 2) Enables consolidation of output from many documents - Textract normalizes keynames and column headers when extracting data from invoices and receipts, into a standard taxonomy. For example, it detects that “invoice no.” “invoice number” and “receipt #” are identical and outputs “INVOICE_RECEIPT_ID,” so that downstream applications can easily compare output from many documents, and 3) Extracts line item details, even when the column headers are missing - Textract extracts line items including items, quantities, and prices of individual goods purchased from an invoice or a receipt. If the table of line items does not include column headers, Textract now infers what the column headers are meant to be based on the table content.
As described in the announcement.
This makes it easier for systems which are integrating Textract to manage expense analysis with the consolidated information.
Implementing Textract with NodeJS SDK
In this walkthrough, we will be using the AnalyzeExpense and AnalyzeDocument API from Textract.
To get started, you can navigate to Amazon Textract AWS Console from where you will be able to run Textract on sample documents and view the response pretty-formatted on the console.
Image used for the demo -

When using AnalyzeDocument from the console/ SDK API, you would have to use what type of feature you want to extract. From SDK API you would have to pass the input for FeatureTypes as TABLES or FORMS, if you are trying this from the console, you can additionally extract all the text as RAW TEXT also.
Raw text -
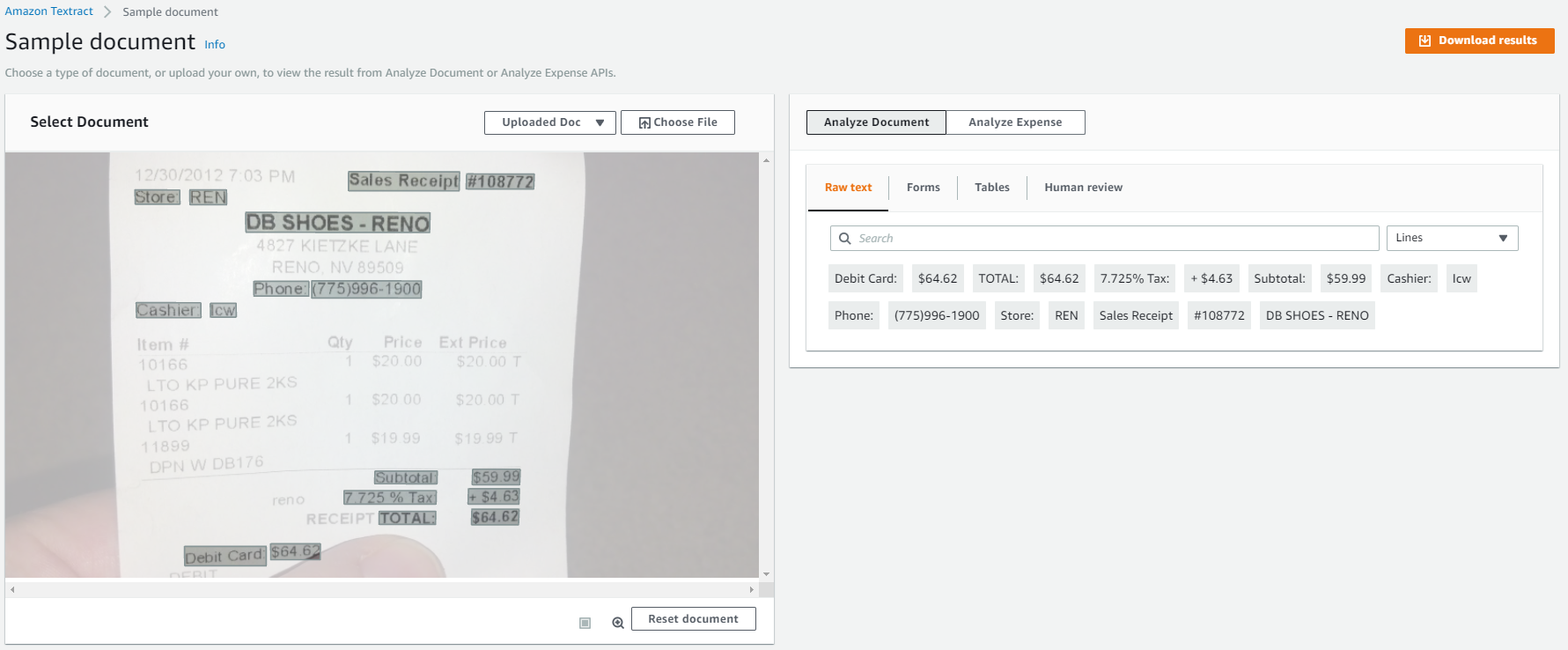 Forms -
Forms -
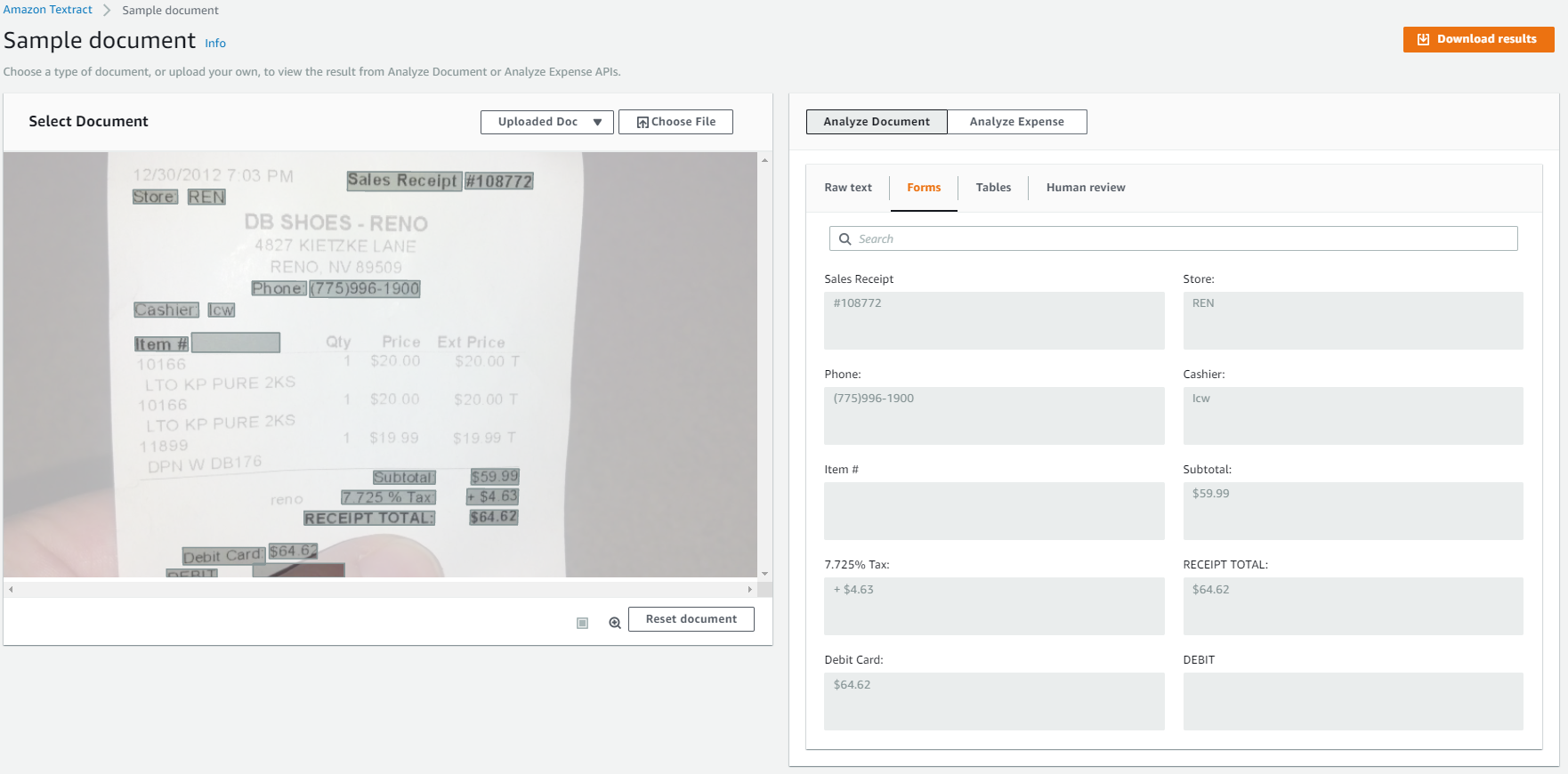 Tables -
Tables -
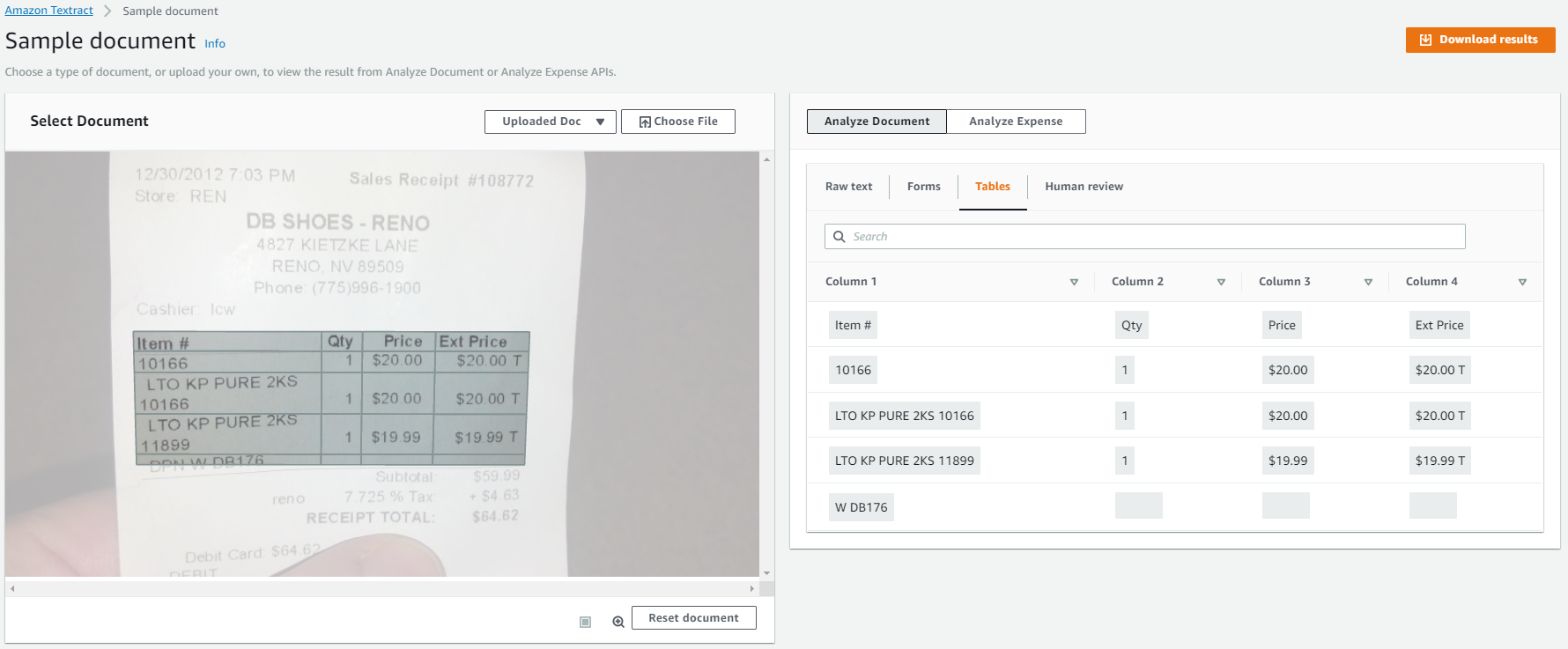
var params = {
Document: {
S3Object: {
Bucket: 'xxxxxx',
Name: 'download.jfif',
}
},
FeatureTypes: ["TABLES", "FORMS"]
};
let response = await textract.analyzeDocument(params).promise()
return response
Response available on GitHub Gist
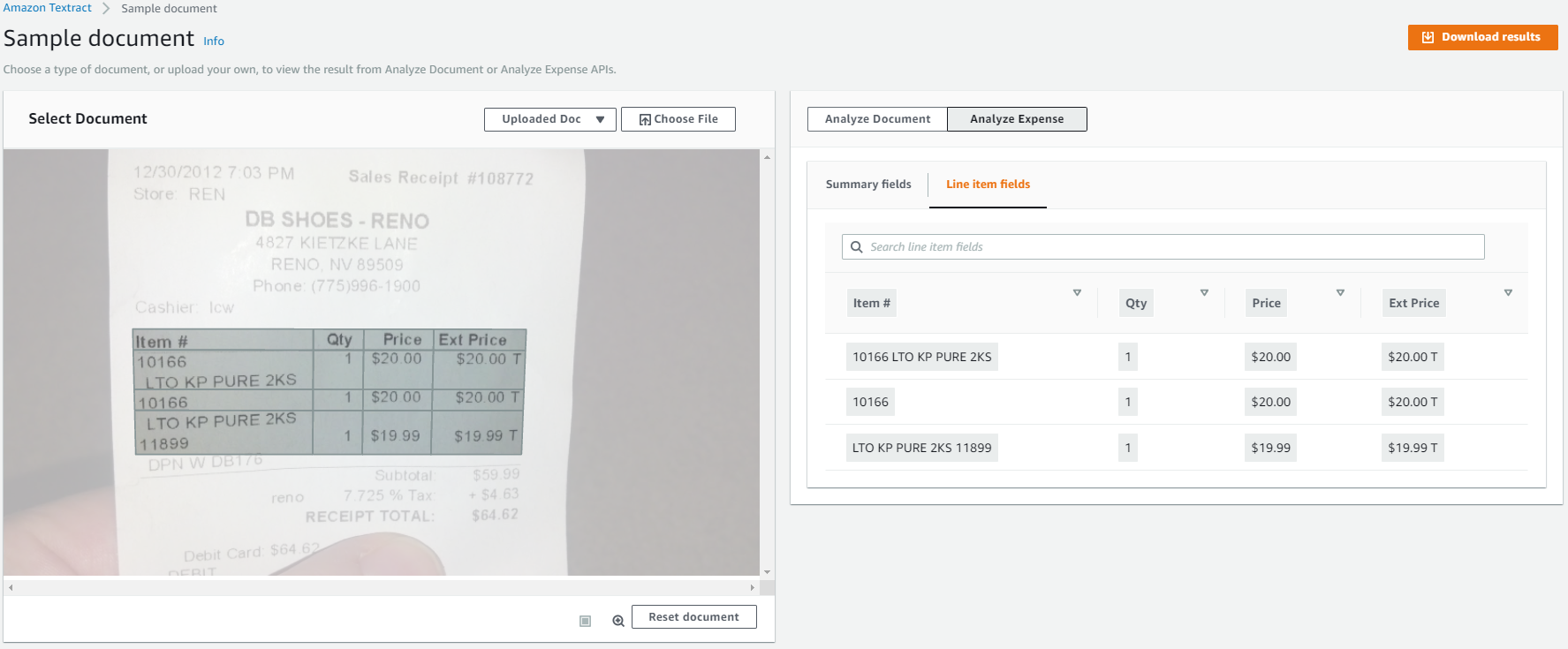
For AnalyzeExpense API, from the console and SDK API, you will get the response with both SummaryFields and LineItemFields.
Summary fields -
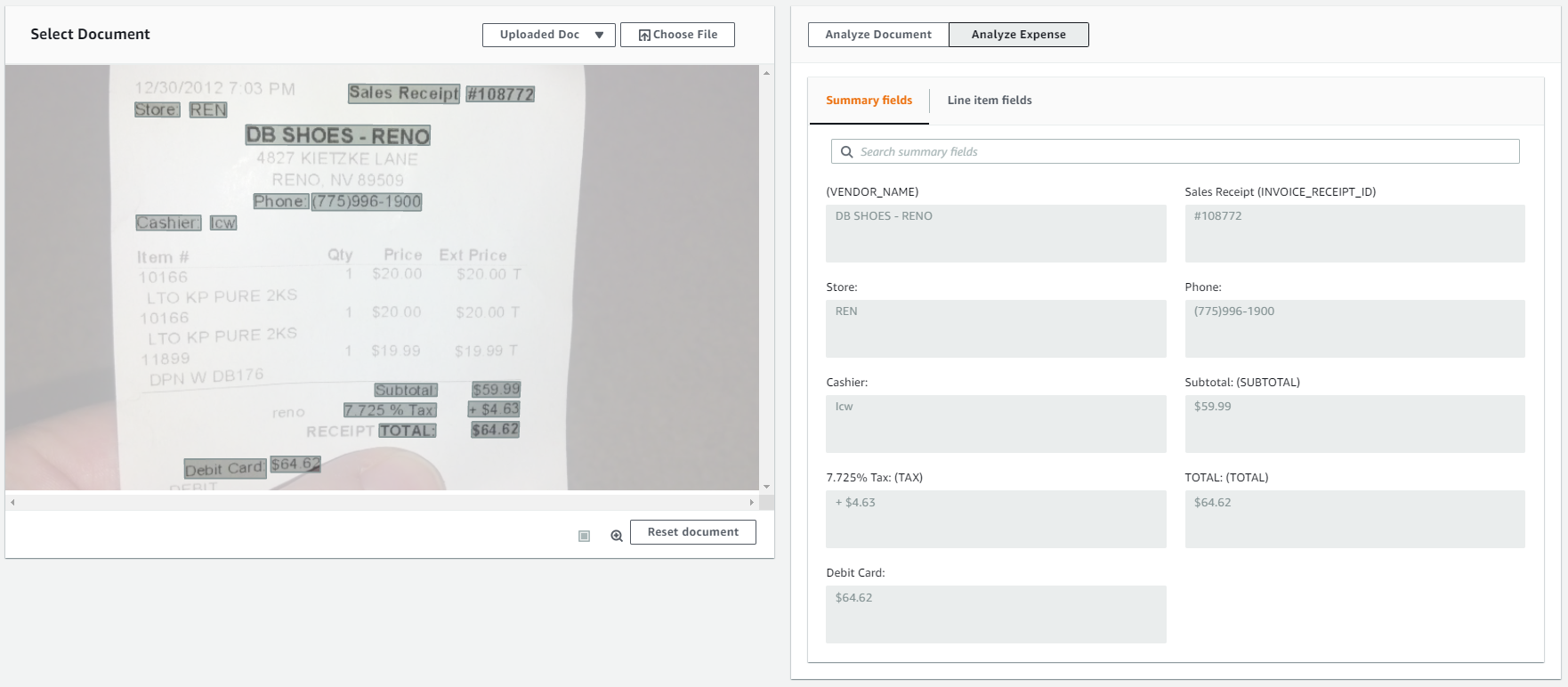 Line item fields
Line item fields
var params = {
Document: {
S3Object: {
Bucket: 'xxxxxx',
Name: 'download.jfif',
}
},
};
let response = await textract.analyzeExpense(params).promise()
return response
Response available on GitHub Gist
Pricing
Amazon Textract's pricing varies upon the API that is executed as internally it uses OCR technology to process and extract textual information. Also based on the feature type, it focuses to extract either FORM or TABLE data.
Detailed information on pricing is available on Textract pricing page.
Conclusion
Amazon Textract enables applications to integrate with SDK APIs so that the documents or images with textual data from various representations of text in form of raw text, forms, tables are easily extratable. Now with the expense analysis support, Textract goes a level ahead to consolidate the items and also extract key information from the invoice or receipts. Textract also provides the confidence level / percentage of the extracted text making it a choice for the integrating applications to either consider it or neglect it.




